|
|
Korenine / Origin / Herkunft |
|


| © korenine.si | Podpora |
|
||||||||||||||
| Origin | Conference | News | Proceedings | About us | Links | Donations |
|
|
|
BASE TEN COUNTING AS THE EXTENSION OF THE ARCHETYPICAL BASE FIVE SYSTEM OF BASQUES AND SLAVS
Petr Jandáček 127 La Senda Rd, Los Alamos, NM 87544, USA
Abstract The Basque and Slavic words for "FIVE" are derived from their words for "hand" or "fist". Their words for "SIX" contain the vestigial feature of "with". Both the Basque and Slavic words for "SEVEN" actually mean "with two more". Numerals beyond four in non-Slav Indo-European languages have lost the sense of etymology derived from this manual and digital concept. While the RHYME and REASON for naming numerals is preserved in Slavic only, other parts of the phonemic structure of the numerals had been largely maintained in all Indo-European languages without the speakers' understanding of the etymology. Thus, deep within the common Base Ten counting system is the archetypical Basque and Slavic Base Five arithmetic arrangement.
To RHYME or not to Rhyme That is the question ... When counting from one to ten and beyond.
Introduction Nineteenth Century scholars (mostly German and English) chose number 100 (hundred) to segregate Indo-European languages into two superfamilies: SATEM (the Avestian word for “One Hundred” and CENTUM {KENTUM} (the Latin word for “One Hundred”). They noticed that the way Indo-Europeans count is “conservative” or resistant to change. With little trouble a native speaker of Icelandic can match the sounds uttered by a speaker of Hindi - representing numerals (if he is told what the task is). Thus, from the most northwestern region to the southeastern regions of the Indo-European territory one can discern the roots of a common counting system. Bad grammar but good colloquial advise in English advances an adage: “If it ain’t broke - don’t fix it". This principle of linguistic conservatism suggests that structure is maintained rather than contrived deliberately. Teachers of grammar are always frustrated by the tyranny of usage.
Slavic counting It has evidently escaped the notice of the 19th Century (and later) linguists that the conservatism in counting also includes (in select Indo-European languages) a uniformity of endings, which in Slavic languages act as a rhyme cf. Table 1, which is taken from Schellen [1]. The rhyme integrates the endings. The Slavic rhyming of endings seems deliberate and poetic. In all the Slavic languages, the numerals 3 and 4 categorically rhyme with the ending "RI"; the numerals 5 and 6 might have rhymed with the ending "E*T", where the asterisk indicates the possibility of the pristine existence of sound S in both numerals; the numerals 7 and 8 categorically rhyme with the ending "-M" or on rare occasions they rhyme with ending "-N", where the - sign indicates the one and the same vowel; and the numerals 9 and 10 categorically rhyme with the ending "ET". It is a matter of record that the Slavic languages use the (RI / E*T / -M / ET) endings in counting. This rhyming rule seems to be so demanding that on the rare occasion that there was a shift or spontaneous drift in pronunciation of one in the pair of rhyming numerals, the other member of the pair was made to match phonemically the ending of its mate. Why there was an insistence on this "RI / E*T / -M / ET" rhyme in the psycholinguistic collective mindset of the ancient Slavs remains a mystery. I have met no Slav thus far who was consciously aware of the "RI / E*T / -M / ET" rhyme, nor who was aware of the archetypical Base Five within the common Base Ten counting system, nor who could come up with a satisfactory (or even unsatisfactory) explanations for these phenomena. Hitherto I shall refer to these phenomena as The RHYME and REASON of SLAVIC counting. There is no room for speculation about the rhyme. “RHYME and REASON” are commonly the criteria applied to logic by English speakers. Speculation plays a bigger role when we look for the reasons for how we named our numerals. Candor dictates that I confess that I have absolutely no idea why our ancient ancestors systematized numerical endings into groupings or pairs. Perhaps the coupling, mating, binary arrangement of the system can somehow be linked to the Slovenian and Sanskrit “dual” which is sandwiched between "singular" and "plural" numbers. Ultimately, the answers will likely come from the field of psycholinguistics. Significantly, the variants between how one counts in each of the (about thirty) Slavic languages and dialects differ almost not at all! The slight differences consist almost exclusively of where a particular dialect places a diphthong or a palatalization or a stress. One could argue persuasively (based on the counting alone) that there is but one Slavic language with about thirty dialects! (In fact, Slovenian alone has about 40 additional sub-dialects) At this time in Ljubljana, Prague, Cottbus and Vladivostok, Slavic peoples count pretty much the same way. Using Czech as an example, observe that Slavic counting is based on a single fist plus one or two (or more) fingers. In Slavic languages the element "S" or "Z" means "with" or "with more". Czech counting (Read Ĕ as YE): 1 = JEDEN, 2 = DVA, 3 = TŘI, 4 = ČTYŘI, 5 =PĚT, (the Czech word for "fist" is "PĚST") 6 = ŠEST, 7 = SEDM, 8 = OSM, 9 = DEVĚT, and 10 = DESET. In the case of numeral 6 = "ŠEST" there exists the implication that a digit is added to the fist. The Czech word for "yet more" is "JEŠTĚ". Thus ŠEST may be derived from "S JEŠTĚ", which in fact means "with yet more". Numeral 7 is conspicuously derived in Slavic from the concept of "with two" or "with two more"; thusly, in Czech as an example, Masculine gender: 7 = SE DVOUMA muži {with two men}, in Feminine gender: 7 = SE DVĔMI ženy {with two women}, in Neuter gender: 7 = SE DVĔMA okny{with two windows).
Baltic and Sanskrit counting Let us now examine each of the Baltic dialects. The examples are presented in Table 2, which is also taken from Schellen [1]. As immediate examples note that in Old Prussian - a language ancestral to Baltic and Slavic (the region of Old Prussian is the same as the land of the Venedi) all the numerals from four to ten end in “TS”. In Sudovian (Yotvingian) {a close relative of Old Prussian} all the numerals from four to nine end in “EI”. Similar conditions exist in Lithuanian and Latvian. In Sanskrit, the words for “two”, “five”, “seven”, “eight”, “nine” and “ten” all end in “A”. By the time we get to Hindi and Punjabi (derivatives of Sanskrit) there are no more common endings retained for the numerals [2].
Other IE counting In tables compiled by Schellen [1] (not shown), we observe that linguistic conservatism related to counting has survived in Balto-Slavic and Sanskrit to a higher degree than in Germanic, Romanic, Celtic or other branches of the I-E languages. The rhyme has disintegrated in the other Indo-European languages. Compared to the Slavic uniformity, the Germanic similarities of EIN / ONE; ZWEI / TWO; DREI / THREE are more remote. Whereas counting in Slavic is integrated, counting in Germanic is disintegrated. The mutation of the Germanic languages in general, and counting in particular may be explained by migrations - for instance: Angles, Saxons and Jutes to Britain. Perhaps, counting is in Romanic languages a little less disintegrated - largely because of the recent Roman hegemony and its continuation by the Church of Rome.
Basque counting Basque is a non-Indo-European language. A cursory examination of the Basque language would suggest at most an accidental connection between Slavic and Basque. There is, on the other hand, an unusually high correspondence among words, which surely would have already existed in antiquity. These include such words as relating to body parts, geographical features, agricultural terms, and the lexicon of hunters and gatherers in general [3,4]. The Basque numerals are as follows: 1 = BAT, 2 = BI or BIGA, 3 = HIRU, 4 = LAU, 5 = BOST, 6 = SEI, 7 = ZAZPI or ZAZPIKO, 8 = ZORTZI, 9 = BEDERATZI, 10 = HAMAR or HAMARREKO [5]. Interesting parallel is that in Basque 5 = BOST, whereas the Basque word for "hand" is "BOSTEKO". On the other hand, the element "S" or "Z" in both Basque and Slavic languages means "with" or "with more". This indicates that like the Slavic also the Basque counting is based on a single hand plus additional one or two (or more) fingers. In the case of 6 = SEI, the implication is that a digit is added to the hand or fist. Exactly the same construct is present in Slavic for their "SJEST" (six). Numeral 7 = ZAZPI or ZAZPIKO is conspicuously derived in Basque from the concept of "with two" or "with two more", thusly 7 = Z BI or Z BIGA. Exactly the same construct is present in Slavic for their "SE DVOUMA", "SE DVĚMA" or "SE DVĚMI" ® "SED-M" (seven). Numeral 8 = ZORTZI with a bit more imagination may be derived from 8 = Z HIRUtzi. There is also another possibility. In antiquity there evidently was a trade language (like Swahili is now in sub-Saharan Africa), elements of which are still present in Basque and Slavic languages. If so, the Basque word for 8 = "ZORTZI" may be "ZE TRZI", a very Polish looking "with three". An interesting side bar is the fact that the Basque word for 11 = HAMAIKA also means "many".
Other aspects of counting Perhaps it had escaped the reader’s notice that the English word “one” conforms remarkably well to the Slavic personal pronouns “ON”, “ONA”, and “ONO” meaning “he”, “she”, and “it”. It also integrates well with “EN”, “UNO”, “EIN”, where it may function as either “Number One” or an Article. Slavic and other Indo-European languages categorically have words for “one” which reflect the Slavic singular gendered personal pronouns. Please notice the similarity between the Slavic “PRST” (finger) and the English word “FIRST”. “DRUG” as a “companion” in some Slavic languages is a good model for TWO, DVA, DO, DEUX, ZWEI etc. The Polish words for “fist” > PIĘŚĆ and “five” > PIĘĆ are very difficult to distinguish (for people who are not Polish). The Polish words for “five” and “fist” both sound in English like something between "pinch" and "punch". In all of the other Slavic languages the words for FIVE and FIST are quite close. In the German FAUST & FÜNF or in the English FIST and FIVE the similarities are more remote. PYAT or PED in Slavic languages can mean "span" (as a hand with stretched out fingers) {rozpjat, razpet} and they are similar to the word for “five”. S JEŠTĚ is the Czech for with yet or with yet more. To me this appears as a likely candidate for ŠEST, the common Slavic word for “six”. If the argument for six does not seem compelling - consider SE DVĚMA or SE DVOUMA or SE DVĚMI (with two) as the root for SED-M, (the Slavic word for “seven”). OS-M rhymes with SED-M and “V” present in some Slavic languages in VOS-M means inside. Thus, eight is the number with seven inside. DEVĚT (Nine) and DESET (Ten) have the same “ET” ending. DESET may be a corruption of DVE pĚSTE (two fists). STO (Hundred) has the “ST” element as in “deSeT ". TISÍC (Czech), TISOČ (Sln) may be a corruption of DESET-SET ® TISET-SIts. Certainly, this is all rather speculative, but I am not aware of better REASON to go with the RHYME. Indicative are also the so-called Roman numerals: I, II, III, IV, V, VI, VII, VIII, IX, and X. Here, "I" may represent a finger, "V" may represent a fist, "VI" a fist plus a finger, "VII" a fist plus two fingers, "VIII" a fist plus three fingers, whereas "X" may represent two fists, a "V" and an inverted "V", i.e. "L", put one above the other. An interesting side bar is the fact that at least one, a westernmost Slavic dialect (Resian) forms the numerals 40, 60, and 80 in the way: 2×20, 3×20, and 4×20 [6], as the Basques [5] and partly also French do.
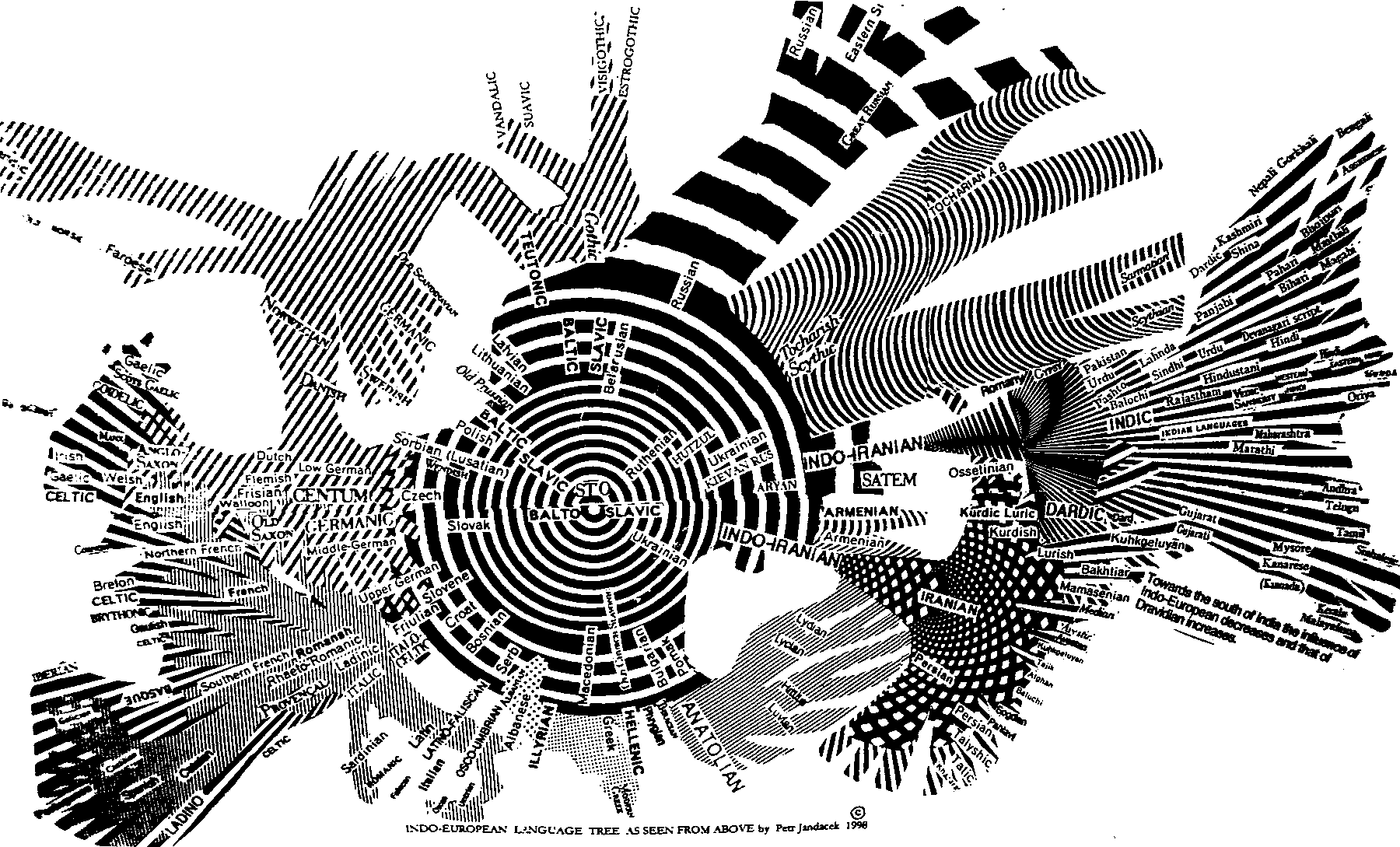
Discussion We have discovered the phenomenon that in Slavic languages as well as in Basque, counting is based on a single fist plus one or two (or more) fingers. In Basque as in Slavic languages the element "S" or "Z" means "with" or "with more". Thus in the case of numeral 6, there is the implication that a digit is added to the fist. On the other hand, in Slavic it may mean also "with yet more". Numeral 7 is conspicuously derived in Basque and Slavic from the concept of "with two" or "with two more". It is also reasonable to speculate that the numeral 8 in Basque is derived from the concept "with three". In all Slavic languages the "RI / E*T / -M / ET" rhyme of numerals is observed. Baltic, Sanskrit and Basque also tend to have consistent endings of some of their numerals, whereas other Indo-European languages do not. Based on this observation, we can divide the Indo-European languages into two groups: On the one hand there are the languages, which have uniform (rhyming or non-rhyming) endings for their numerals: Baltic, Slavic, Sanskrit and Basque belong to the group that has numerical endings configured and integrated. On the other hand there are the Germanic, Romanic, and other languages that have the endings disfigured and disintegrated. Still, the words for numerals in these languages resemble the Slavic ones. An interesting side bar is the fact that the first group (minus the Basque) roughly corresponds to the SATEM half of the Indo-European languages, whereas the second group is CENTUM. It is unlikely that thousands of years ago some Indo-Europeans conspired to impose a binary rhyme or uniform endings of numerals. It is a counterintuitive idea that the Slavs segregated themselves from other Indo-Europeans with the contrivance of the "RI / E*T / -M / ET" rhyme. It rather is likely that the original Proto-Indo-European tongue had this feature of rhyme for numerals. The Slavs had a compulsion to maintain the phonemic pairs so that if one member of a pair spontaneously mutated and drifted out of the rhyme, they (the Slavs) took measures to remediate the situation by a sound shift in the numeral partner. We observe that the linguistic conservatism has survived in Balto-Slavic and Sanskrit to a higher degree than in Germanic, Romanic, Celtic or other branches of Indo-European languages. The immobility of the Slavic counting is indicative of the immobility of Slavic populations in the past. On the other hand, we can extrapolate back into Indo-European prehistory and speculate that ancient languages also had matching endings. Using the arguments derived above by comparing counting as well as using the conclusion regarding the immobility of Slavic people in the past, we can construct an Indo-European languages tree based on these arguments. It is presented in Fig. 1. The combination of map of western Eurasia and language tree reveals that the Slavic languages and their territory are central to the Indo-European community, and that the other Indo-European languages are peripheral branches which in time and space had modified the original numerical and linguistic traditions. Why did the things happen in Indo-European languages? Usually, when conditions change, an organism or a population has only three options to deal with a change. It can die or become extinct. It can migrate to a location where conditions are more similar to the situations to which the organism or population was adapted. Or it can adapt to the new situation. For example, when tidal pools dried up during the Mesozoic ... The fish that lived in the pools mostly became extinct ... Some migrated into the near-by oceans and some started to breathe air. The fact that Slavic languages changed so very little (from other Slavs) and from the original Indo-European model testifies to the stability of their location and life style. Obviously the Slavs are autochthonous to their geographic area. Their long history and prehistory of agriculture did not necessitate changes in language. Their languages evolved slowly and differentiated very little. Why change if things are just fine? The sharks did not change for hundreds of millions of years because the circumstances of their oceans did not change much. Along the periphery of the Slavic Indo-Europeans there was a lot more going on! There the Slav-like peoples differentiated more and more from the original agrarian model as they encountered deserts and oceans and jungles and foreigners who spoke Dravidian, Semitic, Turko-Tatar, Finno-Ugrian, Uralic, Altaic, Sino-Tibetan or other language forms. Navigation, war, and survival in desert, as well as conflicts with dissimilar populations were hard won lessons, which the new and more experienced Indo-Europeans used to subjugate their rural Slavic ancestors. The new and improved Indo-Europeans had better political and military skills and organizations. They knew how to pillage and sail and fight. Their differentiated languages reflected their superior skills and technology and they soon used the Slavic agricultural base to create political entities and states. They enslaved the Slav-Slaves. The Slavs became the vazals - vasals bound to the land. Thus for the last 3 or 4 thousand years Germanic, Romanic and Celtic lords ruled over the aboriginal Balto-Slavic populations. This pattern persisted into modern times with the Greco-Roman Empires, Visigoths, The Order of Teutonic Knights, Drang nach Osten, etc. Slavic languages themselves began to change as they were influenced by Romanic, Germanic or Celtic contact. Thus, German influenced and produced Czech and Polish and Italian had impact on Montenegro, and other Adriatic Slavs. This explains in greater detail why 1. The Slavs are centrally located, 2. Why the Slavic languages diversified less than the peripheral branches. 3. Why the Slavs did not undergo lifestyle changes that would necessitate the changes of lexicon of hunters and gatherers and simple agrarians, which they share with the Basques. Military, nautical, commercial, aristocratic and such terminology the Slavs largely adopted from other Indo-Europeans together with the expertise in trade, sailing, war and government.
Fig. 1
Conclusions Slavic differs from other Indo-European languages in at least four ways: 1. The Slavs have remained more uniform than Italic, Germanic or other speakers of Indo-European languages. Slavic languages are mutually intelligible in counting and based on this feature all may be considered as a single language with many dialects. 2. Slavs show vestiges of Base Five within the common Base Ten system. The Slavs share this feature with the Basques. 3. The Slavs rhyme their words for 3&4, 5&6, 7&8, and 9&10. 4. We may find the origins of Indo-European words for numerals in ancient Slavic etymology.
Acknowledgement Helpful suggestions and technical help of Professor A. Perdih as well as Andrej Perdih are thankfully acknowledged.
References 1. R.J. Schellen, Balto-Slavic Numerals, http://members.tripod.com/rjschellen/BaltSlavNums.htm 2. J.Skulj & J.C. Sharda, Indo-Aryan and Slavic Affinities. In: Zbornik prve mednarodne konference Veneti v etnogenezi srednjeevropskega prebivalstva [Proceedings of the First Topical Conference The Veneti within the Ethnogenesis of the Central-European Population], Jutro, Ljubljana 2002, pp 112-121. (ISBN 961-6433-06-7) 3. P. Jandáček & L. Arko, Linguistic Connections Between Basques and Slavs (Veneti) in Antiquity. In: Zbornik prve mednarodne konference Veneti v etnogenezi srednjeevropskega prebivalstva [Proceedings of the First Topical Conference The Veneti within the Ethnogenesis of the Central-European Population], Jutro, Ljubljana 2002, pp 151-166. 4. P. Jandáček, Equipment of Ötzi in Basque and Slavic. In: Zbornik posveta Praprebivalstvo na tleh Srednje Evrope [Proceedings of the Conference Ancient Settlers of Central Europe], Jutro, Ljubljana 2003, pp 17-20. 5. Aulestia, Gorka & White, Linda: Basque-English --- English-Basque Dictionary, University of Nevada Press, Reno, Nevada, 1992. 6. F. Megušar, Rezijani nas vodijo v predzgodovino slovenskega prostora, Drevesa, 1-2/2000, 15-16.
Povzetek Štetje na desetiški osnovi kot podaljšek štetja na petiški osnovi pri Baskih in Slovanih Baskovske in slovanske besede za število 5 (PET) izhajajo iz besed kot sta ROKA in PEST. Besede za število 6 (ŠEST) imajo ostanke besed S ali SE in PEST. Baskovske in slovanske besede za število 7 (SEDEM) dejansko pomenijo ŠE DVA (ali DVA VEČ). Števila višja od 4 (ŠTIRI) izpeljana iz osnovnih pojmov v zvezi z roko in prsti so izgubila besedotvorni pomen v vseh indo-evropskih jezikih, razen v slovanskih. Čeprav se tega ljudje na splošno ne zavedajo, sta v slovanskih jezikih ohranjena tako rima kot razlog za poimenovanje števil, medtem ko so pri štetju v drugih indo-evropskih jezikih ohranjene samo glasovne prvine jezika. V sedanjem štetju po desetiškem sistemu je pri Baskih in Slovanih skrit prvotni način štetja na osnovi števila PET.
Table 1. Some Slavic Dialects [1]
Old Slavic & Eastern Slavic Dialects
West Slavic Dialects
South Slavic Dialects
Few Slovenian Dialects**
** Some incorrect identification of dialects in ref. [1] is corrected here.
Table 2. Baltic Dialects [1]
|